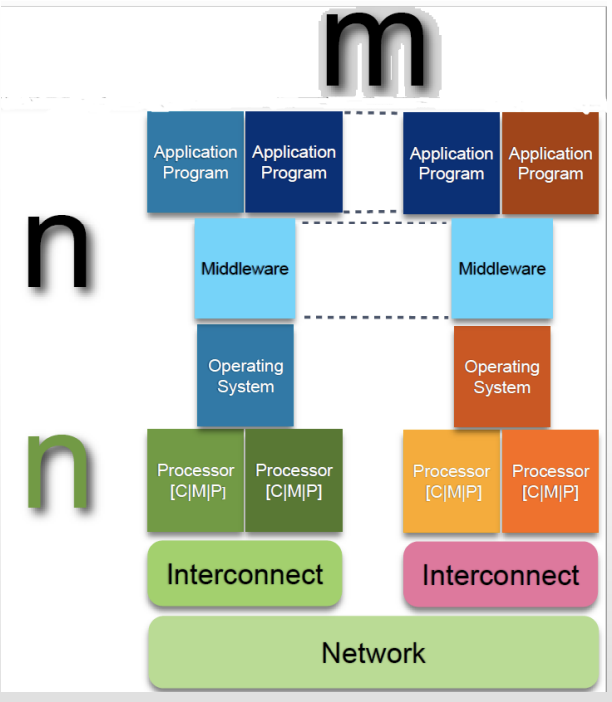
Architectures of Distributed Systems
- An obvious way to distinguish between distributed systems is on the organisation of their software components, in other words, their software architecture
- Centralised architectures (eg. traditional client-server)
- Decentralised architectures (eg. p2p)
- Hybrid architectures
Software Architectural Styles
- A software architectural style is formulated in terms of components, the way that components are conencted to each otters, data exchange between components, and how elements are jointly configured into a system
- A variety of architectural styles
- Layered architectural styles
- Object-based architectural styles
- Resource_centered architectural styles
- Event-based architectural styles
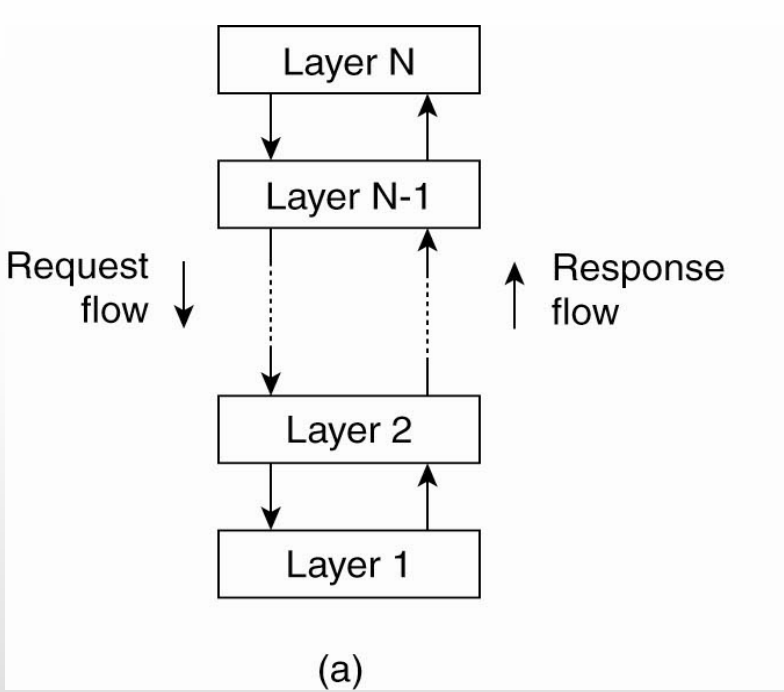
Layered Architectural Style
Lj can make downcall to Li (i<j) and expects a response
bottom layers provide services to top layers
request flow from top to bottom, response from bottom to top
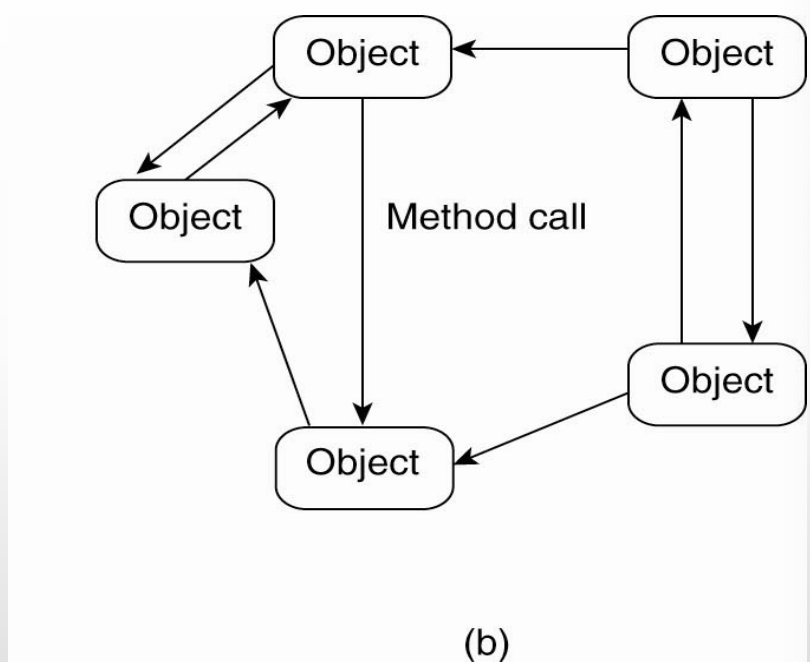
Object-Based Architectural Style
each object coresponds to a component, and component connect through procedure call in a network
provides a way of encapsulating data and operations into a single entity
Communication happen as method invocations, called Remote Procedure Calls (RPC)
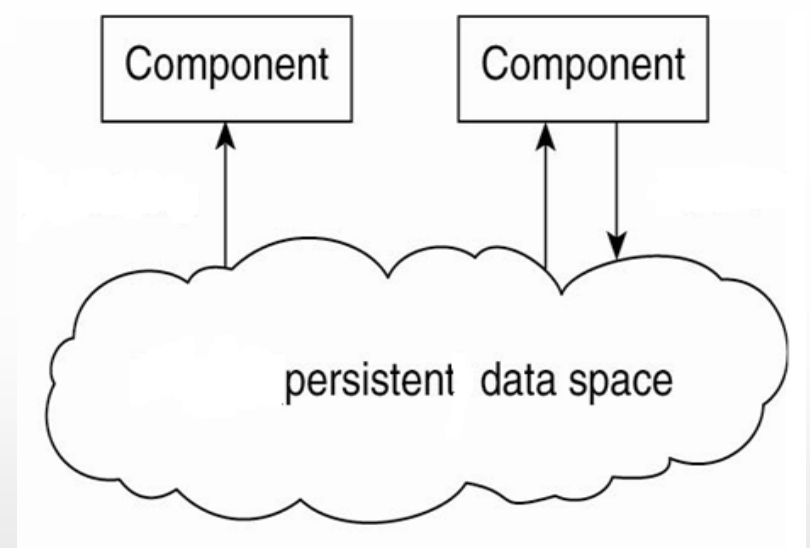
Resource-Centered Architectural Style
A DS is viewed as a huge collection of resources that individually managed by components
based on a data centre
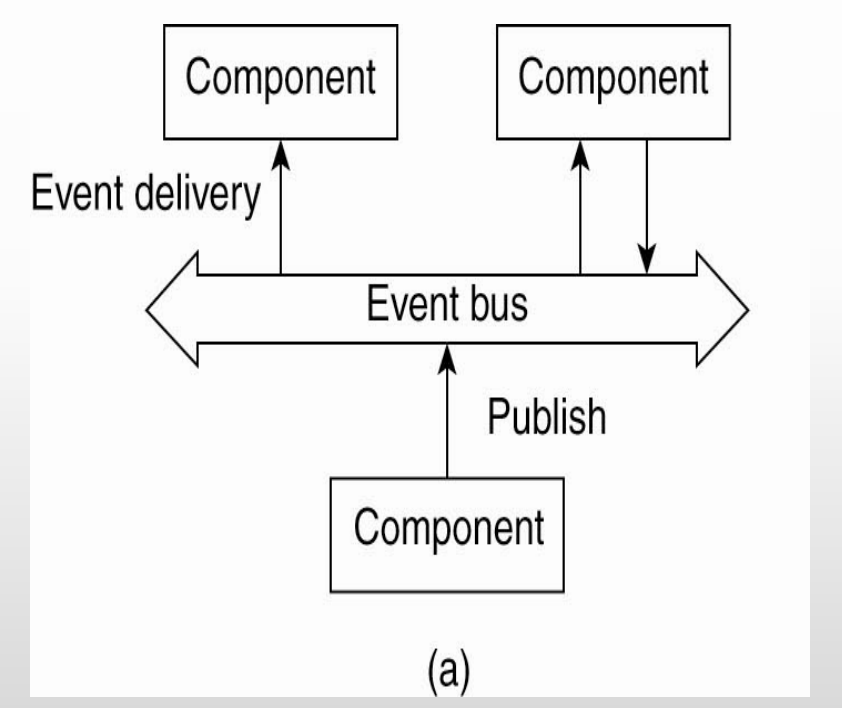
The Event-Based Architectural Style
processes running on various components are both referentially decoupled and temporally coupled, one process does not explicitly know any other process
the only thing a process can do is publish a notification describing the occurence of an event
processes may subscribe to a specific kind of notification
Centralised System Architecture
- A server and a client
Multi-Tiered Client-Server Architectures
- Three logical tiers
- Two types of machines
- a client machine
- a server machine
- All functinality is handled by the server, client is no more than a dumb terminal
- Many distributed applications are divided into the three layes
- user interface layer
- processing layer
- data layer
- The main challenge to clients and servers is to distribute these layers across different machines
- A server may sometimes act as a client
Decentralised System Architectures: P2P
- better workload balance
- a client or server may be physically split up into a number of logical parts, this is horizontal distribution
- each process will act as a client and a server
- processes are organised in an overlay network
- two types of overlay networks:
- structured
- unstructured
Structured P2P Systems
- nodes are organised in an overlay that adheres to a specific, deterministic topology (eg. a ring, a binary tree, a grid etc)
- topology used to efficiently loop up data
- and node can be asked to loop up a given key
Unstructured P2P Systems
- each node maintains an ad hoc(临时的) list of neighbours, eg. random graph
- changes its local list almost continuously
- searching for data is necessary
Examples of Searching Methods
- Flooding
- Random Walks
Making Data Search more Scalable in Unstructured P2P
- to improve scalability of data search, it make use of special nodes that maintain an index of data items, creating special collaborations among nodes
Collaborative Distributed Systems
- BitTorrent (download from other users until form a complete file)
- global directory
- contains a link to the file tracker, a server of active nodes
Edge-Server Systems
- following properties
- Are deployed on the internet
- servers are placed “at the edge” of the network
- helps reduce latency, bandwidth usage and improves overall performance